Writing a SQL query that returns ten rows is software development. Writing a system that processes one million rows per hour without data loss is data engineering.
The distinction isn't about difficulty — it's about focus. Software developers build features that users interact with. Data engineers build infrastructure that makes data accessible, reliable, and usable at scale.
This guide clarifies the key differences between a data engineer and a software developer: scope of work, core technologies, project cycles, collaboration patterns, problem-solving depth, salary potential, and remote opportunities.
5 key differences between a data engineer and a software developer
Both data engineering and software development roles involve writing code and solving technical problems.
But their focus areas, tools, and career outcomes differ significantly. Confusing these paths leads to mismatched job applications, wasted certification investments, and lower compensation than your skills deserve.
At a glance, here’s how the two roles compare:
Scope of work and focus area
Data engineers architect systems that collect, transform, and deliver data at scale. As a data engineer, you build ETL/ELT pipelines that process millions of records and design data warehouses that analysts query for insights. You also ensure data quality, consistency, and availability across these systems.
Software developers build applications that solve user problems. As a software developer, you create features users interact with directly and design APIs that connect different services. You also implement business logic that drives product functionality.
The fundamental difference: data engineers build infrastructure that enables insights. Software developers build products that deliver value.
Technical stack and tools
Data engineers master specialized tools for data processing. SQL is your primary language for querying and transforming data. Python handles pipeline orchestration and data validation.
Spark processes distributed datasets across clusters, Airflow schedules and monitors workflows, and Kafka streams real-time events. Meanwhile, cloud platforms like AWS, GCP, and Azure host your data infrastructure.
Software developers work across broader application stacks. Frontend developers use JavaScript, React, and Vue for user interfaces. Backend developers build APIs with Python, Java, or Node.js.
Full-stack developers handle both. Version control, testing frameworks, and CI/CD pipelines support development workflows.
So while data engineers optimize for throughput and reliability, software developers optimize for user experience and feature velocity.
Collaboration and stakeholders
Your communication patterns shift dramatically between roles. Data engineers coordinate with data scientists who need clean datasets for models. You’ll work with analysts who query warehouses for reports, support ML engineers who require training data pipelines, and discuss infrastructure costs with platform teams.
Software developers sync with product managers who define features and collaborate with UX designers on user flows. You’ll coordinate with QA teams on testing strategies and present technical trade-offs to business stakeholders.
Data engineers enable data-driven decisions. Software developers ship features that users experience.
Education and credentials
Data engineering roles increasingly require an understanding of distributed systems and data architecture. Computer science degrees help, but many data engineers transition from software development, database administration, or analytics roles.
Cloud certifications in AWS, GCP, or Azure data services prove platform expertise. Understanding of data modeling, ETL design patterns, and SQL optimization matters more than formal credentials.
Software development offers flexible entry paths. Bootcamp graduates, self-taught developers, and CS degree holders all compete for positions. Framework-specific knowledge and demonstrated project experience often matter more than formal education.
Both paths value practical experience. But data engineering emphasizes infrastructure thinking while software development emphasizes product building.
Skills and core responsibilities
As a data engineer, your daily work centers on building a robust data infrastructure:
- ETL pipeline development: Extract data from APIs, databases, and third-party services. Transform records to match target schemas and business rules. Load processed data into warehouses where analysts can query it.
- Data warehouse design: Architect storage schemas that optimize query performance. Implement star, snowflake, or denormalized schemas based on access patterns and business requirements.
- Real-time data streaming: Build Kafka pipelines that process events as they occur. Handle millions of messages per hour while maintaining ordering guarantees and exactly-once delivery semantics.
As a software developer, your focus stays on building products and features:
- Application development: Write code in languages like JavaScript, Python, Java, or C#. Implement features that meet product specifications while maintaining code quality and test coverage.
- API design and integration: Build RESTful or GraphQL APIs that expose application functionality. Integrate third-party services for payments, authentication, messaging, or analytics.
- Testing and debugging: Write unit tests, integration tests, and end-to-end tests that prevent regressions. Debug production issues using logs, monitoring tools, and systematic troubleshooting.
As a software developer, you build features that solve problems, improve experiences, or enable new capabilities.
Typical career paths
Most professionals start as junior data engineers and build straightforward ETL pipelines under senior guidance. Here’s how careers typically progress:
- Data engineer: Build and maintain production pipelines that process company data daily. Own ETL workflows, monitor data quality, and support analysts who depend on reliable data delivery.
- Senior data engineer: Architect complex multi-source pipelines and mentor junior team members. Make infrastructure decisions that affect data availability, costs, and performance across the organization.
- Data architect: Design enterprise-wide data strategies that span cloud platforms, on-premise systems, and vendor integrations. Set technical direction for how organizations store, process, and govern data.
For software developers, career progression follows these common paths:
- Software developer: Own features from specification to deployment. Write clean code, fix bugs, and participate in technical design discussions. Build expertise in specific frameworks or domains.
- Senior software developer: Architect complex features and mentor junior team members. Make technical decisions that affect application structure, performance, and maintainability.
- Software architect: Design system-wide architectures that span multiple services and teams. Ensure technical decisions support long-term business goals while managing complexity.
Specialization options include frontend, backend, full-stack, mobile (iOS/Android), game development, embedded systems, or DevOps engineering.
Beyond writing codes and queries: why judgment about data correctness can't be automated yet
Software development and data engineering both involve writing code. Both require technical depth. Both solve complex problems. But there's a fundamental difference in what you're actually optimizing for — and it's this difference that makes certain types of expertise irreplaceable by AI.
When you write application code, correctness is often verifiable: Does the button work? Does the API return the correct response? Does the payment process? Tests can catch most bugs. Code review catches design issues. Production monitoring catches performance problems.
When you work with data at scale, correctness is subtle: Is this the correct data? Are these the right transformations? Will this logic hold when edge cases appear in production? The code might run perfectly while producing completely wrong results.
This is where human judgment still dominates, and where AI-generated solutions consistently fail in ways automated testing can't yet catch.
Why AI struggles with data infrastructure problems that humans solve instinctively
AI coding tools can now generate SQL queries, scaffold ETL pipelines, and write transformation logic. The syntax is correct. The code runs. But the generated solutions can consistently miss judgment calls that experienced engineers make automatically.
Consider a simple request: "Write a query to get daily active users."
An AI might generate:
This works. It returns numbers. But an experienced data engineer immediately asks questions the AI never considered:
What timezone are we counting in? User events have timestamps. Do you convert to UTC before grouping by date? Do you use the user's local timezone? Do you use the company's reporting timezone? Each choice produces different numbers, and only one matches the business's actual definition of "daily."
How do you handle users who never log in but are still active? Mobile apps often stay logged in. Users might generate events for days without a login event. Should those count as active? The AI optimized for the literal request, not the underlying question.
What about duplicate events? Sources sometimes retry failed requests. Your events table might have duplicates. Do you deduplicate before counting? After? Does your DISTINCT handle that, or do you need additional logic?
How far back should this query look? No date filter means scanning the entire table. That's fine with 10,000 rows. With 10 billion rows, this query times out — or worse, returns results after burning through your monthly compute budget.
These aren't advanced problems. They're the basic questions data engineers ask before writing any query. But they require understanding how data systems actually work in production — knowledge that comes from debugging pipeline failures, investigating metric discrepancies, and seeing how "technically correct" code produces wrong business insights.
AI models don't have that experience. They pattern-match against code they've seen, but they can't reason about the hidden assumptions in data pipelines or anticipate the ways queries fail at scale.
Where software development and data engineering both require judgment AI lacks
The problem isn't unique to data engineering. It shows up everywhere code interacts with messy reality:
In application development: AI can generate authentication codes that work in testing but fail when users have special characters in their passwords, when session tokens expire during long-running operations, or when the database connection pool is incorrectly under load.
In API design: AI can scaffold endpoints that handle happy-path requests but don't account for idempotency, rate limiting, or what happens when clients retry failed requests.
In database queries: AI can write joins that work correctly but scan entire tables instead of using indexes, or produce query plans that perform well with test data but degrade catastrophically with production volumes.
In system architecture: AI can suggest patterns that work for the current scale but create bottlenecks as traffic grows, or designs that look clean but make operational problems harder to debug.
The pattern is consistent: AI can generate code that compiles and passes tests, but lacks the judgment that comes from maintaining systems in production, debugging failures at 3 AM, and learning which "clean" solutions create technical debt.
This gap between "works" and "good" is where human expertise remains valuable — and where companies need evaluators who can articulate what's missing.
Why your production experience makes you valuable to AI development
Models improve by learning from engineers who can explain not just that generated code is wrong, but why it's wrong and what would make it better.
If you've maintained systems that process millions of records daily, you can judge whether AI-generated code will actually work at production scale or just in testing.
This judgment isn't about memorizing best practices or following style guides. It's pattern recognition built from seeing how different technical choices play out in production — which optimizations worked, which abstractions became maintenance nightmares, which "correct" solutions caused outages.
Whether you're a data engineer who understands pipeline reliability or a software developer who knows application architecture, your production experience can directly shape what AI systems learn about writing maintainable, scalable code.
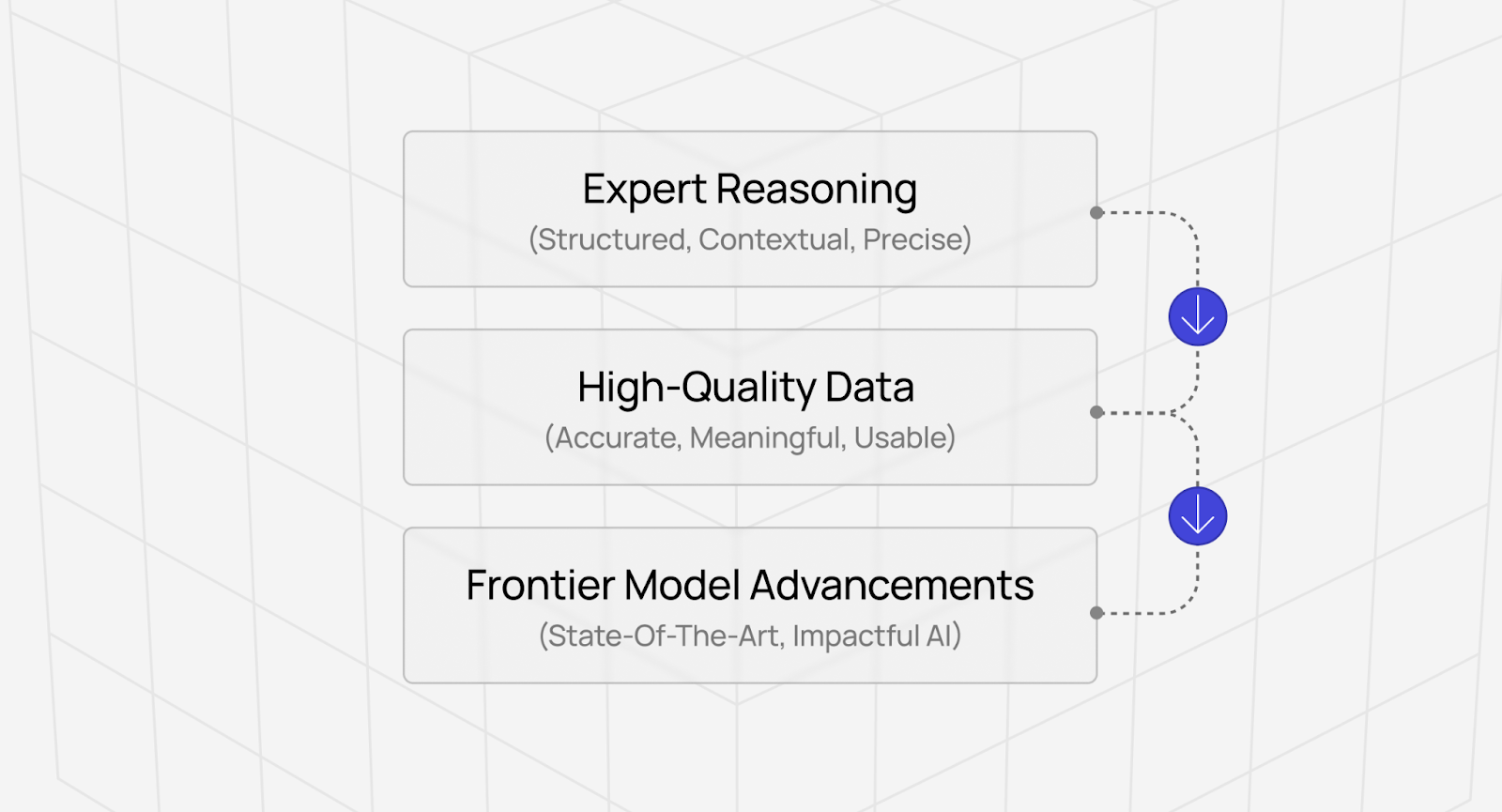
The work isn't about protecting your job from automation. It's about ensuring AI tools learn to distinguish between code that compiles and code that actually solves problems correctly in production environments.
How to get an AI training job?
At DataAnnotation, we operate one of the world’s largest AI training marketplaces with over 100,000 AI trainers working remotely. To source AI trainers, we operate a tiered qualification system that validates expertise and rewards demonstrated performance.
Entry starts with a Starter Assessment that typically takes about an hour to complete. This isn't a resume screen or a credential check — it's a performance-based evaluation that assesses your ability to do the work.
Pass it, and coding projects start at $40 per hour for code evaluation and AI performance assessment across Python, JavaScript, HTML, C++, C#, SQL, and other languages.
You can choose your work hours. You can work daily, weekly, or whenever projects fit your schedule. There are no minimum hour requirements, no mandatory login schedules, and no penalties for taking time away when other priorities demand attention.
The work here at DataAnnotation fits your life rather than controlling it.
Explore premium coding projects at DataAnnotation
If you want to work where code quality determines frontier AI advancement, at DataAnnotation, we‘re at the forefront of AGI development, where your judgment determines whether billion-dollar training runs advance capabilities or optimize for the wrong objectives.
When you evaluate AI-generated code, your preference judgments influence how models balance helpfulness against truthfulness, how they handle ambiguous requests, and whether they develop reasoning capabilities that generalize or just memorize patterns.
This work shapes systems that millions of people will interact with.
If you want in, getting started is straightforward:
- Visit the DataAnnotation application page and click “Apply”
- Fill out the brief form with your background and availability
- Complete the Starter Assessment
- Check your inbox for the approval decision (which should arrive within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. We stay selective to maintain quality standards. Just remember: you can only take the Starter Assessment once, so prepare thoroughly before starting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI — and you have the expertise to contribute.
.jpeg)