

Most "best LLM for coding" comparisons rank models by benchmark scores and context windows as if selecting a coding assistant is a spreadsheet exercise. Claude Sonnet 4.5 achieves 77.2% on SWE-bench Verified. GPT-5 scores 74.9%.
But does it mean that picking the highest number solves the problems?
Developers using these models daily see something different. The same model that scores highest on SWE-bench can introduce security vulnerabilities that pass code review. The model-topping code-generation leaderboards can fail to distinguish elegant implementations from those that create technical debt.
Benchmarks measure what's quantifiable on standardized tests. They don't measure what determines whether generated code actually ships or gets rewritten.
We operate an evaluation infrastructure at DataAnnotation that assesses AI-generated code across Python, JavaScript, C++, and other languages for labs building frontier models. The work involves expert developers evaluating millions of code outputs. The patterns that emerge don't align with benchmark rankings.
This examines which models actually produce code that ships, why they fail in specific ways, and what benchmark scores miss about real coding workflows.
How does expert evaluation determine which coding LLMs actually work
Large language models for coding are AI systems trained on repositories of source code, documentation, and programming discussions to assist developers with code generation, debugging, refactoring, and technical problem-solving.
For developers, that manifests as autocomplete suggestions that sometimes read your mind, debugging conversations that sometimes solve problems in minutes, and code generation that sometimes produces exactly what you needed and sometimes produces confident garbage that takes hours to untangle.
But here's what the marketing obscures: every coding LLM is only as capable as the human evaluation that shaped its training.
When GPT-5 generates a Python function that handles edge cases correctly, that capability emerged from millions of instances where human evaluators identified where AI-generated code broke, explained why certain implementations create memory leaks while others scale cleanly, and rated outputs on correctness, efficiency, and maintainability. The model learned what "good code" means by absorbing these human judgments; judgments that required genuine programming expertise, not pattern matching.
This applies to Claude, Gemini, DeepSeek, and every model on the leaderboards. Their coding abilities reflect not just the volume of training data, but also the quality of expert feedback that taught them to distinguish elegant solutions from code that merely compiles.
The distinction matters because it explains the gap between benchmark performance and your actual experience. A model trained primarily on competitive programming feedback will excel at algorithmic puzzles but struggle with production concerns like error handling, logging, and graceful degradation. A model trained with feedback from senior engineers who understand distributed systems will catch concurrency bugs that benchmark-optimized models miss entirely.
The benchmark says one thing. Your production incident tells another story.
Why benchmark comparisons fail developers
The industry has developed sophisticated benchmarks: SWE-bench tests real-world bug fixes across GitHub repositories. HumanEval measures function generation accuracy. LiveCodeBench evaluates competitive programming. Aider Polyglot tests code editing across multiple languages.
These tools serve a purpose. But they share a fundamental limitation we see constantly in AI training work: they optimize for what's automatable to verify, not what matters in production.
Consider what happens when a model scores 88% on Aider Polyglot. That sounds impressive until you realize the benchmark doesn't capture whether the model understands why certain boundary conditions matter; it just checks if output matches expected values for the test suite. The same model might generate syntactically correct code that passes basic tests but fails when handling null inputs, timezone boundaries, concurrent access patterns, or that one weird legacy system your company acquired many years ago.
We see this pattern constantly in code evaluation work. An AI-generated function might solve a LeetCode problem perfectly but introduce subtle bugs when adapted for production use, race conditions that only manifest under load, memory leaks that accumulate over hours, and edge cases that slip through unit tests because nobody thought to write them. Catching these failures requires precisely the kind of expert judgment that automated benchmarks can't replicate.
The context window numbers tell a similar story. Gemini 2.5 Pro supports a million tokens, which is impressive until you realize that context length and context utilization are entirely different capabilities. A model might accept your entire codebase in a single prompt while still missing dependencies between files, forgetting constraints mentioned early in the context, or introducing inconsistencies during a large refactoring operation.
Then there's the hallucination problem. A model might confidently generate code using an API that doesn't exist, reference a library function with incorrect parameter types, or implement a solution based on documentation from three versions ago. OpenAI reports GPT-5 hallucinates 4.8% of the time. However, in coding, a single hallucinated API can break an entire application.
Here's what nobody discusses: benchmark optimization creates perverse incentives that can make models worse at real work. Labs tune models to top SWE-bench the same way companies once optimized for keyword density in SEO. The benchmark becomes the goal rather than the proxy. This is why benchmark positions shift constantly without corresponding shifts in developer experience.
What actually determines which LLM writes the best code
With those failure modes understood, selecting the right model becomes less about benchmark rankings and more about matching model behaviors to your specific workflow. The differences that matter aren't captured in leaderboard positions; they're in how models fail, when they ask for clarification, and what kinds of mistakes they make.
Claude Sonnet 4.5 (Anthropic)
Every debugging session follows the same frustrating pattern: you paste an error, the model generates a fix, the fix introduces a new bug, you paste the latest error, the model generates another fix that breaks something else. Two hours later, you're worse off than when you started.
Claude Sonnet 4.5 breaks this cycle by outlining reasoning before making edits. The model explains what it thinks is wrong, proposes a fix, and identifies potential side effects—giving you the chance to catch mistakes before they compound.
On benchmarks, Claude leads SWE-bench Verified at 77.2% in standard runs and 82% with parallel test-time compute. Anthropic reports the model can maintain focus on complex, multi-step tasks for over 30 hours. But the behavioral pattern matters more than the numbers: Claude tends to ask for clarification on ambiguous requirements rather than guessing.
Where Claude Sonnet 4.5 excels
The transparent reasoning process makes it easier to catch logical errors before they become code errors. When Claude outlines its understanding of the problem, you can correct misconceptions before they propagate through the solution.
Conservative handling of ambiguity prevents confident but wrong outputs. Rather than guessing what you meant and generating code that looks right but isn't, Claude asks clarifying questions. This feels slower in the moment, but saves hours of debugging.
Extended focus for complex tasks means the model maintains coherent reasoning across multi-hour sessions without losing context or contradicting earlier decisions. For debugging sessions that span multiple files and require tracking state across many interactions, this consistency matters.
Where Claude Sonnet 4.5 breaks down
The same careful reasoning that prevents hallucinations adds unnecessary latency to simple requests. When you just want a quick function and don't need the explanation, Claude's thoroughness becomes overhead.
Infrastructure reliability issues in late 2025 prompted some developers to seek alternatives. The service has improved, but teams that experienced outages during critical work have been slower to return.
Premium pricing means Claude costs more per token than most alternatives. For high-volume usage or cost-sensitive teams, the quality advantage may not justify the expense for routine tasks.
Best for: Developers working on complex debugging sessions, multi-file refactoring, or migration projects where introducing new bugs is expensive. If you've ever wasted hours because a model confidently gave you a wrong answer, Claude's conservative approach trades speed for reliability.
GPT-5 (OpenAI)
Most developers need a model that just works for everyday tasks; autocomplete that's usually right, explanations that are usually helpful, code that usually runs. GPT-5 optimizes for this workflow.
The unified architecture combines reasoning capabilities with fast responses, using real-time routing to decide when deep thinking is needed versus quick completion. GPT-5 achieves 74.9% on SWE-bench Verified and 88% on Aider Polyglot, a one-third reduction in error rate compared to o3.
More meaningfully, it achieves these scores with 22% fewer output tokens and 45% fewer tool calls than o3 at high reasoning effort. Efficiency matters for developer workflow—a model that solves problems with less back-and-forth integrates more smoothly into actual coding sessions.
Where GPT-5 excels
Efficient problem-solving reaches correct answers with fewer iterations. The 400K-token context window enables repository-scale analysis, while the routing system applies deep reasoning only when needed, keeping simple tasks fast.
Strong frontend capabilities consistently outperform alternatives. For UI work, responsive design, and modern frameworks, GPT-5 has a domain-specific advantage that benchmarks don't fully capture.
Balanced speed and accuracy make GPT-5 a reliable daily driver. Real-time routing means you're not paying the latency cost of deep reasoning for tasks that don't need it.
Where GPT-5 breaks down
Overconfidence on edge cases means the same efficiency that makes GPT-5 fast can manifest as wrong answers delivered with high confidence. The model that "just works" 95% of the time can waste hours when it doesn't.
Response times are slower than GPT-5 Mini. For autocomplete-style usage where latency matters more than reasoning depth, the full model adds overhead you may not want.
Complex multi-step implementation plans still require human oversight. Don't trust it to architect an entire system without review at each stage; the confidence that makes it fast doesn't always correlate with correctness.
Best for: Developers who want a reliable daily driver, something that handles 90% of tasks well without constant supervision. If you're building frontend interfaces, prototyping quickly, or need explanations alongside code, GPT-5 balances capability with usability.
Gemini 2.5 Pro (Google)
Legacy codebases create a specific nightmare: thousands of files, years of accumulated decisions, and nobody who remembers why that one service exists. Understanding enough to make safe changes requires holding an impossible amount of context in your head.
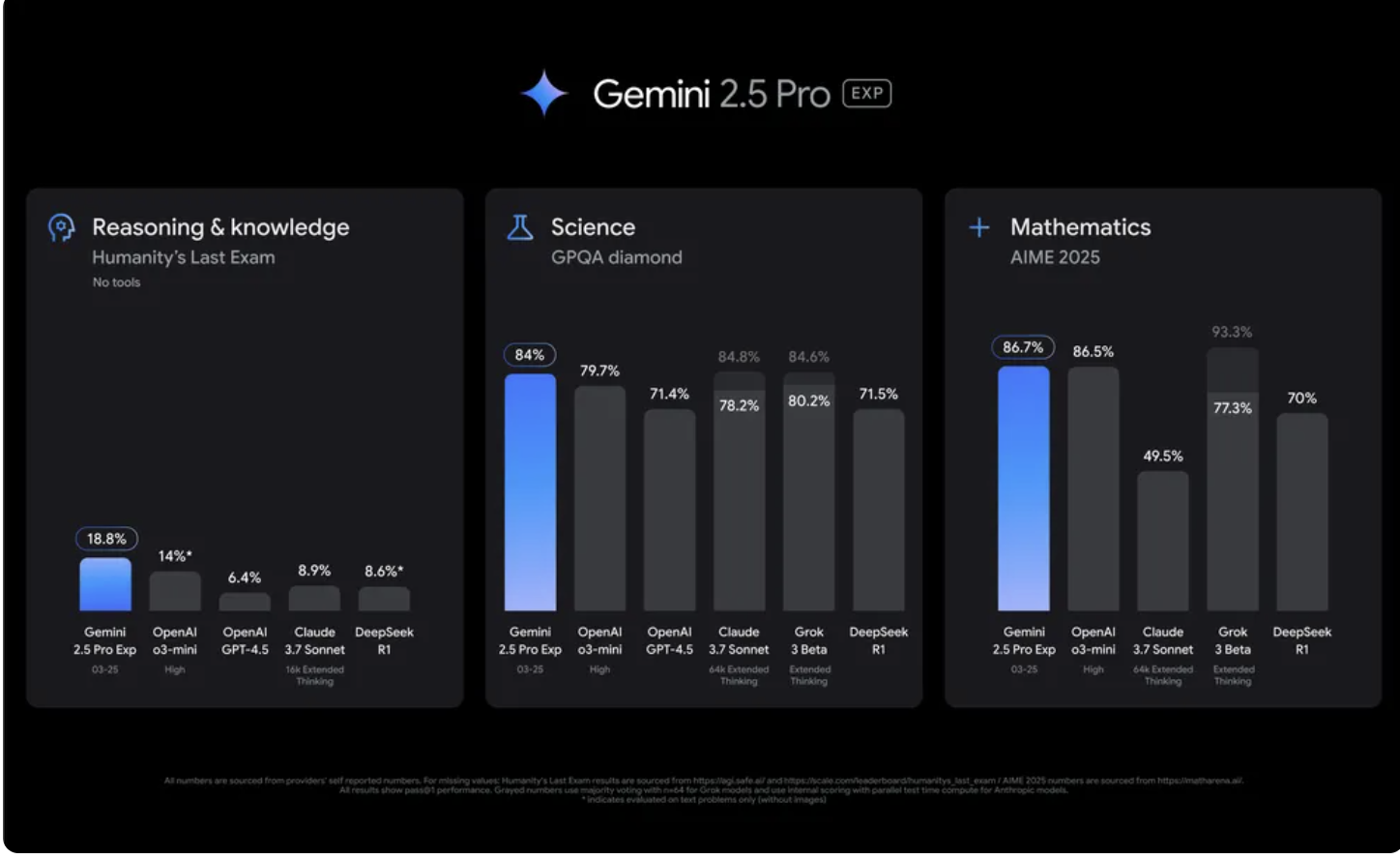
Gemini 2.5 Pro ships with a million-token context window, the first model capable of accepting this scale. For repository-scale operations, entire test suites, migration scripts and multi-file refactoring, nothing else processes this volume in single passes.
Google reports the model can comprehend vast datasets and handle complex problems from different information sources, including text, audio, images, video, and entire code repositories.
Where Gemini 2.5 Pro excels
Unmatched context capacity enables processing entire codebases, test suites, or documentation sets in a single prompt without chunking or summarization. For problems that require understanding how dozens of files interact, the context window is the capability.
Native multimodal input means you can include architecture diagrams, error screenshots, and whiteboard photos directly in prompts. Real development workflows involve visual documentation that text-only models can't process.
Controllable reasoning depth through Deep Think mode lets you trade latency for accuracy when correctness matters more than speed. Integration with Google's ecosystem (Docs, Drive, Colab) reduces friction for teams already in that stack.
Where Gemini 2.5 Pro breaks down
Context length doesn't equal reasoning quality. We've evaluated thousands of multi-file tasks, and the pattern is consistent: models that can technically hold more context don't necessarily reason coherently across it. Gemini might accept your entire codebase while still missing dependencies between files.
Verbose outputs can bury essential details in unnecessary elaboration. When you need a specific answer, wading through extensive explanations adds friction rather than clarity.
Unprompted code modifications sometimes introduce bugs. Gemini occasionally changes code you didn't ask it to change, requiring careful review of diffs before accepting suggestions.
Best for: Teams working with large, interconnected codebases, legacy audits, major migrations, or any task requiring understanding across dozens of files. If your problem is "I need to understand this entire system before I can safely change anything," Gemini's context window is the capability.
DeepSeek V3/R1

Running experiments costs money. Every variation you test, every approach you try, every dead end you explore, it all adds up. At premium model prices, experimentation becomes a budget line item rather than a natural part of development.
DeepSeek changes this math entirely. The current API pricing runs $0.28/million input tokens and $0.028/million for cache hits, which is an order of magnitude cheaper than Claude or GPT.
The Mixture-of-Experts architecture activates only a fraction of parameters for each token, dramatically reducing computational costs. The R1 variant, fine-tuned with reinforcement learning for reasoning, approaches frontier-level performance on algorithmic tasks.
Where DeepSeek excels
Dramatically lower costs enable running 20–50× more experiments, variations, or batch jobs for the same budget. At these rates, experimentation becomes a natural part of development rather than something that requires approval.
Strong algorithmic reasoning makes the R1 variant particularly capable for problems requiring step-by-step logical deduction. For competitive programming style tasks or mathematical reasoning, R1 approaches frontier performance at a fraction of the price.
Open-source availability under the MIT license allows self-hosting, modification, and integration without vendor lock-in.
Where DeepSeek breaks down
Less precise instruction following means the same efficiency that reduces costs, and it also reduces nuance in complex requirements. DeepSeek may miss subtleties that Claude or GPT would catch.
Verbose reasoning mode produces unnecessarily long chain-of-thought outputs. For tasks where you just need the answer, the reasoning overhead adds tokens without adding value.
Security considerations require careful review for sensitive codebases. For proprietary code, additional scrutiny is warranted before routing through external APIs.
Best for: Teams with cost sensitivity, high-volume batch processing needs, or algorithmic workloads. If you're running automated pipelines, experimenting heavily, or need "good enough" at scale rather than "perfect" at premium prices, DeepSeek enables workflows that other models make prohibitive.
Llama 4 (Meta)
Some code can't leave your servers. Proprietary algorithms, regulatory requirements, competitive secrets; the reasons vary, but the constraint is absolute: no external API calls.
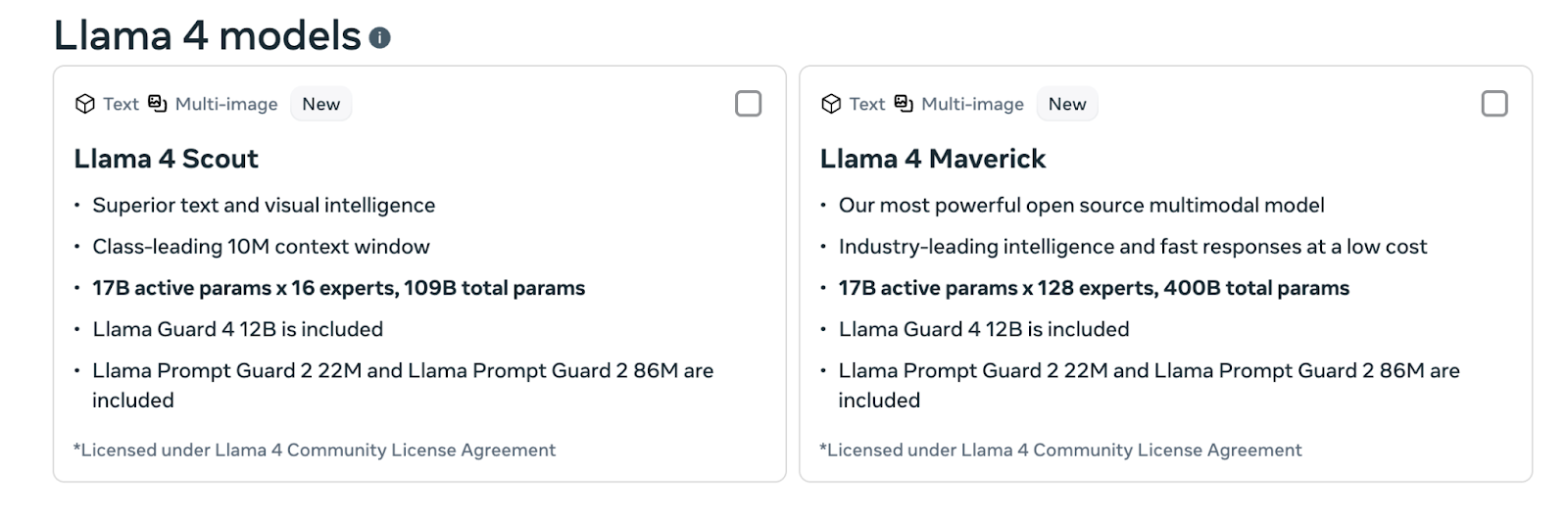
Meta's Llama 4 offers open weights enabling local deployment and custom fine-tuning. For organizations that can't send code externally, regulated industries, defense contractors, and companies with strict IP policies, Llama provides capabilities that closed models structurally cannot match.
Where Llama 4 excels
Complete data control means code never leaves your infrastructure, satisfying even the strictest security requirements. For organizations where external API calls are prohibited, this is required.
Custom fine-tuning potential allows training on your codebase to get a model that understands your specific patterns and conventions. A Llama model fine-tuned on your code will outperform any generic model on your specific work.
No vendor lock-in means you own the deployment entirely. Changes in external pricing, terms, or availability don't affect your operations.
Where Llama 4 breaks down
The open model tax is real—expect performance gaps versus Claude and GPT on general tasks. For straightforward coding assistance, closed models typically produce better results.
Infrastructure investment is significant. Self-hosting demands GPU resources, operational expertise, and ongoing maintenance. The "free" model has substantial deployment costs.
Fine-tuning potential requires actual fine-tuning. The customization benefits only materialize if you do the work—out-of-the-box performance trails closed alternatives.
Best for: Organizations with strict data residency requirements, IP protection needs, or security constraints that prohibit external API calls. If you can't send code to external services for any reason, Llama is often the only viable option.
GitHub Copilot
Context switching kills flow. Every time you leave your editor to paste code into a chat interface, wait for a response, copy the result back, and reorient yourself, you lose minutes and momentum.
GitHub Copilot eliminates this friction. Built on OpenAI's models and trained on GitHub's code corpus, it offers real-time suggestions as you type. Context from your current project, minimal interruption to your workflow, and suggestions that often match what you were about to write.
Where GitHub Copilot excels
Zero context switching means suggestions appear inline without leaving your editor or breaking flow. For developers who measure productivity in uninterrupted minutes, this integration matters more than raw model capability.
Project-aware completions understand your codebase structure and adapt suggestions accordingly. Copilot learns from your acceptance patterns and adjusts to match your coding style.
Lowest friction to adopt of any option, it works in your existing IDE with minimal setup. No API configuration, no prompt engineering, just install and start coding.
Where GitHub Copilot breaks down
The IDE integration trades depth for convenience. Copilot is less capable than using GPT-5 or Claude directly for complex problems that require extended reasoning or multi-step solutions.
Suggestions optimize for acceptance, not correctness. What you're likely to accept isn't always what's right. The feedback loop can reinforce patterns rather than improve them.
Subscription pricing differs from API economics. Unlike pay-per-token models, you can't reduce costs by reducing usage. The flat fee makes sense for heavy users but less so for occasional assistance.
Best for: Developers who want AI assistance integrated into their existing workflow without adaptation. If context switching is your bottleneck and you want completions that feel like a faster version of your own typing, Copilot minimizes friction between thinking and coding.
Matching models to how you actually work
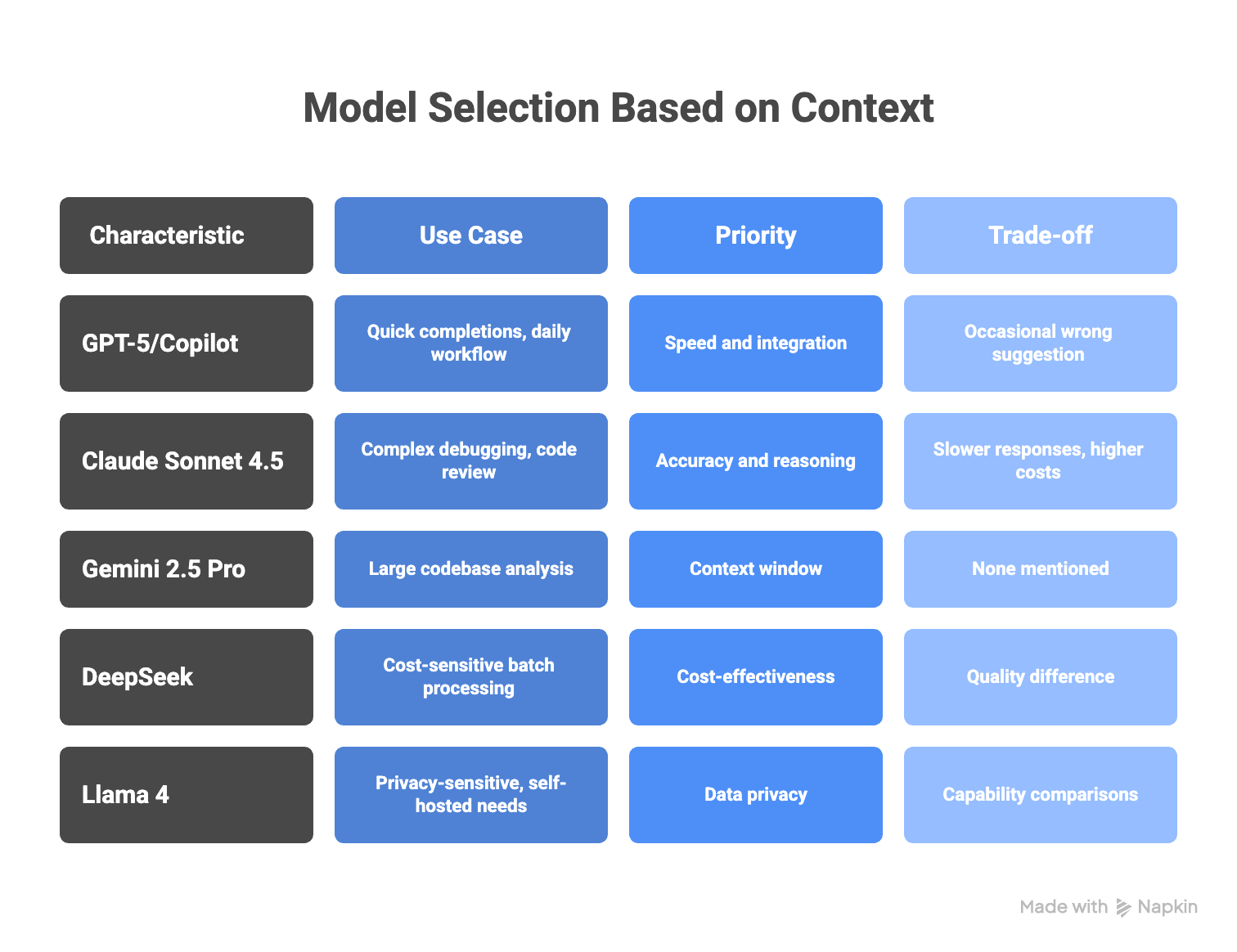
The mistake is treating model selection as a single decision. Most productive setups use different models for different contexts.
- For quick completions and daily workflow, GPT-5 or GitHub Copilot makes sense. Speed and integration matter more than maximum accuracy for routine tasks—the occasional wrong suggestion costs less than the constant friction of a slower tool.
- For complex debugging and code review, Claude Sonnet 4.5 justifies the slower responses and higher costs. When a wrong answer means hours of debugging or a production incident, the careful reasoning pays for itself.
- For large codebase analysis, Gemini 2.5 Pro's context window is the capability. Legacy audits, major migrations, or any task requiring understanding across dozens of files—nothing else processes this volume effectively.
- For cost-sensitive batch processing, route automated tasks to DeepSeek. The quality difference matters less for high-volume pipelines than for human-facing development work.
- For privacy-sensitive or self-hosted needs, Llama 4 is often the only option. If you can't send code externally, capability comparisons are moot.
- The developers getting the most value use Claude for the complex debugging session, Copilot for daily autocomplete, and DeepSeek for the batch analysis job running overnight. Different tools for different problems.
The human evaluation bottleneck
Every improvement in these LLMs' capabilities traces back to human expert evaluation.
When Claude got better at debugging, that improvement came from thousands of instances where human evaluators identified where AI-generated fixes introduced new bugs, explained why certain refactoring approaches create technical debt, and rated solutions on dimensions that automated tests can't capture: maintainability, readability, and alignment with architectural patterns.
When GPT-5 learned to explain reasoning between steps, that capability emerged from expert feedback on what makes explanations actually helpful versus technically correct but unhelpful. Someone had to articulate why one explanation helps developers understand the code while another leaves them more confused.
The bottleneck for AI coding capability is the quality and volume of expert human judgment available to train these systems.
Models trained with feedback from developers who understand production constraints, security implications, and long-term maintainability perform differently from models trained primarily on competitive programming solutions. The gap between benchmark performance and real-world usefulness often reflects the difference between the evaluation tasks used in training and the problems developers actually face.
This creates an interesting asymmetry. Millions of developers pay subscription fees to use these models. A much smaller number contributes to the expert judgment that makes the models useful in the first place.
How AI training at DataAnnotation uses this expertise
AI training, which is about evaluating and improving AI model outputs, is how expert judgment gets encoded into the models developers use daily.
At DataAnnotation, coding projects involve exactly the kind of technical evaluation that determines whether models help developers ship production code or just pass benchmarks. You evaluate code generated by AI systems for correctness, efficiency, and edge case handling. You identify where reasoning breaks down in complex multi-step solutions. You explain why implementations fail, not just that they fail. You rate outputs on dimensions that automated tests miss entirely.
Overall, coding projects require the same deep thinking you apply to production code review, except your evaluations directly improve the AI systems millions of developers rely on.
So which matters more to you?
Subscribing to models trained by other people? Or contributing the expert judgment that makes those models actually worthwhile?
If assessment-based work resonates more than paying subscription fees, and you have the expertise to evaluate code at a professional level, getting started is straightforward:
- Visit the DataAnnotation application page and click "Apply"
- Fill out the brief form with your background and availability
- Complete the Coding Starter Assessment (typically 1–2 hours)
- Check your inbox for the approval decision within a few days
- Log in to your dashboard, choose your first project, and start contributing
No signup fees. DataAnnotation stays selective to maintain quality standards. You can only take the Starter Assessment once, so read the instructions carefully and review before submitting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI, and you have the expertise to contribute.
Frequently asked questions
What are AI code generators?
AI code generators are software tools that use large language models trained on code repositories to generate, complete, and modify code in response to natural-language prompts. They translate human instructions into working code, enabling developers to accelerate routine tasks while focusing attention on complex problems that require human judgment. The quality of these tools depends heavily on the human expert feedback used to train them—teaching models what distinguishes correct, efficient, maintainable code from solutions that merely compile.
What are the best AI code generators for beginners?
GitHub Copilot offers the smoothest experience for beginners with real-time suggestions integrated directly into popular IDEs. The key is selecting tools that explain their suggestions rather than just generating code, this helps develop understanding alongside productivity. GPT-5's tendency to explain reasoning makes it more educational than tools optimized purely for completion speed.
Is AI-generated code secure?
AI-generated code requires human review for security. Models can reproduce vulnerabilities from training data, generate insecure patterns, or implement solutions using deprecated APIs with known security issues. The security risk is structural: models learn from existing code, which contains vulnerabilities. Security validation and adherence to secure coding guidelines remain essential before production deployment, regardless of which model you use.
.jpeg)



