


In this article
You can waste months applying to platforms that pay $5/hour for commodity microtasks, or you can spend an hour understanding what separates gig commodity platforms from technology companies and access work paying $20 to $50+ per hour.
The difference isn't obvious from job listings.
Most platforms in the AI training industry look legitimate: they verify credentials, pay on time, have clean websites, and maintain review scores. But many of them just aggregate workers and lack the technology to measure or improve the quality of frontier AI, and end up paying peanuts.
We've watched this industry grow from the inside, having managed over 100,000 remote workers contributing to frontier AI systems. That scale taught us what separates platforms that pay for expertise from those that exploit it: technology that measures quality.
This guide shows you how to get premium data annotation jobs, what to look for, what capabilities premium assessments actually test, how to demonstrate judgment over checkbox compliance, and why expertise depth matters more than work volume.
1. Build demonstrated capabilities that premium AI training requires
Most guides say "get a PhD degree" or "learn Python." This advice wastes months of your time building credentials that don't really predict performance. Premium platforms measure demonstrated capability through judgment on complex cases, not resume credentials.
Why credentials can correlate poorly with performance on complex tasks
Consider this pattern:
- At DataAnnotation, we’ve seen some computer science PhDs write terrible code because their training emphasizes algorithms and theory rather than production software engineering.
- Hemingway never finished college but wrote better prose than most English PhDs because writing excellence requires taste, not credentials.
- Emily Dickinson had no formal poetry training.
These patterns hold across domains because credentials can correlate poorly with the capabilities premium AI training actually requires.
You might probably remember Google's GoEmotions dataset, which trained sentiment analysis models by labeling emotional content in Reddit comments. The dataset labels "LETS FUCKING GOOOOO" as ANGER when it clearly expresses excitement.
This error occurred because annotators followed surface-level rules about profanity rather than understanding the context. Premium annotators catch this kind of mistake. Credential-focused workers miss it because they're checking boxes against guidelines rather than demonstrating judgment.
What you should practice beyond general work
For writing precision, analyze why professional writing achieves clarity while amateur writing creates confusion — focus on how word choice and structure create meaning, not just whether grammar rules are followed.
For critical reasoning, practice evaluating arguments in domains you understand well, identifying logical gaps and unsupported leaps.
For edge-case attention, develop explicit mental frameworks that consistently handle novel situations, rather than relying solely on intuition.
While learning, continue using these four checklists:
- Taste: Can you identify why one AI response feels generic while another demonstrates genuine insight?
- Street smarts: Can you spot edge cases where rules break down?
- Mental fortitude: Can you spend 30 minutes evaluating a single response when needed?
- Judgment under ambiguity: Can you apply principles to novel situations where guidelines don't give explicit answers?
These four capabilities develop through deliberate practice on ambiguous cases, not through coursework.
For specialized tracks, the capabilities shift:
- Coding work requires recognizing algorithmic elegance over brute-force solutions and understanding when "working code" creates technical debt.
- STEM work requires assessing the quality of scientific reasoning and identifying methodological flaws that fact-checking misses.
- Professional work requires applying the regulatory context and judging contextual appropriateness in ambiguous situations.
These are the capabilities you need to focus on.
Developing judgment through deliberate practice, not coursework
If you have a coding background, your edge isn't writing more code — it's recognizing quality distinctions you developed through years of code review.
If you have a STEM background, your edge isn't memorizing more facts — it's applying evaluative frameworks you learned in your education.
If you have a professional background, your edge isn't knowing more regulations — it's navigating complexity the way professionals do.
The goal isn't an overnight transformation but demonstrable capability on assessment tasks that test judgment rather than memorization.
2. Avoid scams by selecting platforms that measure quality, not just count workers
Most applicants waste time distinguishing obvious scams from legitimate platforms. Guess what the more complex problem is? Legitimate platforms that treat expertise as a commodity.
Think about why some platforms pay $5 per hour while others pay $50 for supposedly identical work. It's not generosity. When platforms can only measure "task completed: yes/no," they compete on price like commodity labor.
However, when platforms can prove that specific workers catch 15% more edge cases than median performers, reduce hallucination rates in production models, or identify context-dependent errors that rule-based systems miss, they can pay premium rates because they demonstrate ROI to AI companies training frontier models.
The distinction matters more than obvious scam warnings.
Body shops vs. technology companies
Real scams are easy to spot:
- Upfront fees for "training materials,"
- Pay below $10/hour, no clear terms page, pressure to start without assessment
When DataAnnotation tells you they pay $20+ for general work, $40+ for coding and STEM expertise, and $50+ for professional credentials, that tier structure isn't arbitrary pricing — it reflects sophisticated algorithms that identify when workers demonstrate genuine expertise versus when they're pattern-matching from training examples.
In any platform, if onboarding focuses only on background verification without any capability demonstration, that's a signal they're counting heads rather than extracting expertise, and will eventually pay you peanuts.
Verify legitimacy through worker feedback
Beyond distinguishing body shops from technology companies, verify fundamental legitimacy through hard sources: Glassdoor and Indeed reviews from current workers, specific payment complaints on r/WorkOnline or Trustpilot, and Better Business Bureau complaint resolution history.
For example, DataAnnotation maintains a 4.1/5 rating on Indeed with 1,500+ reviews and a 3.9/5 rating on Glassdoor with 300+ reviews, where workers consistently mention reliable weekly payments.
3. Pass assessments designed to measure judgment, not checkbox compliance
Most applicants fail qualification assessments not because of a lack of skills but because they are treated like academic tests or checkbox compliance exercises. Premium platforms design assessments to measure the same capabilities they need in production work: judgment under ambiguity, reasoning process quality, and systematic approach to complexity.
What separates judgment from checkbox compliance
Our platform assessments don't really test whether you can follow rules — they test whether you can apply principles to novel situations that guidelines don't explicitly cover. Speed doesn't really matter first (we focus more on quality, velocity comes after).
Here are what matters:
- Time allocation judgment: Can you identify when a case requires 5 minutes versus 30 minutes?
- Reasoning transparency: Can you articulate why you made a judgment call?
- Principle application: Can you extrapolate from stated principles to handle cases the rubric doesn't cover?
- Consistency under variation: Do your judgments reflect systematic reasoning or case-by-case reactions?
With this, DataAnnotation offers track-specific Starter Assessments matching your background:
- General: Tests writing clarity, critical thinking, attention to detail for $25–$30+/hr work
- Coding: Evaluates programming knowledge for projects earning up to $50-$75+/hr
- STEM: Tests domain expertise for $50–$100+/hr work
- Professional: Tests specialized knowledge in law/finance/medicine for $50–$100+/hr opportunities
- Language-specific: Evaluates fluency for multilingual projects at $20–$30+/hr
Most assessments require 60-90 minutes to complete thoughtfully. Specialized tracks may take 90-120 minutes because they test depth rather than breadth. Allocate 2x the estimated time to eliminate rush-induced errors.
Preparation strategy: articulate reasoning over optimizing speed
Here's what preparation looks like in practice:
- Don't optimize for finishing quickly — At DataAnnotation, we measure quality first, not speed.
- Don't try to match imagined "correct answers" — many cases have no single right answer.
- Optimize for articulating the reasoning process clearly (explain why, not just what).
- Identify when cases require deeper analysis (show judgment about time allocation).
- Demonstrate systematic thinking (show how you handle novel situations consistently).
Consider the difference between checkbox compliance and judgment. When a rubric says "prefer responses with citations," the checkbox approach rates AI responses highly just because they contain citations.
However, the judgment approach notices when citations don't actually support the claims made and rates the response poorly because citations serving as credibility theater are worse than no citations — they create false confidence.
Articulating this reasoning demonstrates understanding of why citations matter (verification and credibility), not just that they should be present.
Why one-attempt policies maintain measurement integrity
At DataAnnotation, we allow one assessment attempt per track because the assessment reveals how you work under production conditions. Multiple retakes would let you pattern-match from feedback rather than demonstrating genuine capability.
This isn't arbitrary strictness — it's measurement integrity.
We need to distinguish between workers who understand principles and those who optimize for known test cases. This is why preparation matters: you demonstrate your actual working approach, not your ability to iterate toward a passing score.
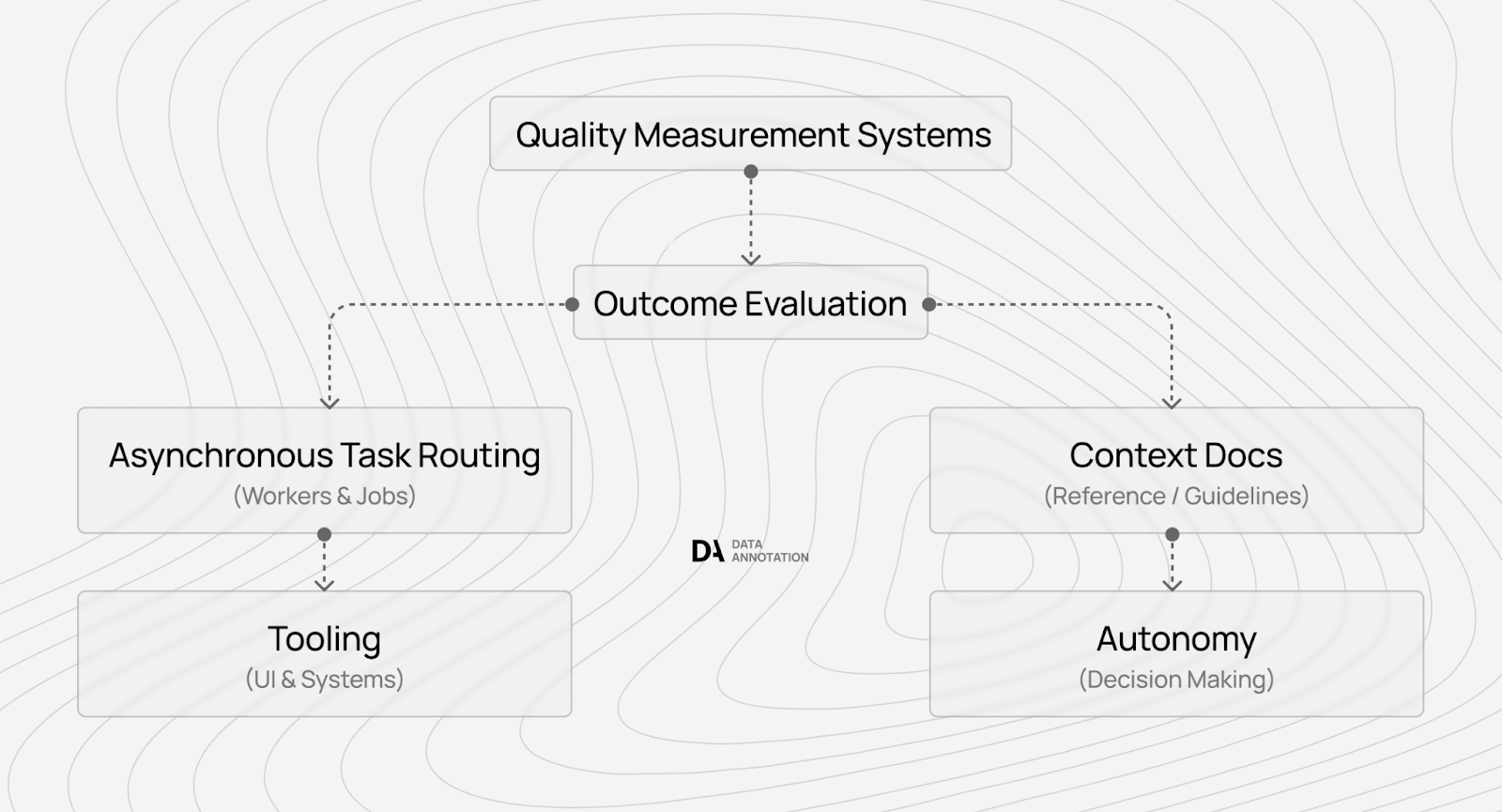
4. Scale through expertise depth, not work volume
Most workers assume "more hours worked = more income earned." This holds for commodity labor priced by time. Premium AI training follows different economics: as models get more sophisticated, the work becomes more complex rather than being automated.
Why the quality ceiling keeps rising as models advance
At DataAnnotation, the quality ceiling keeps rising because we believe quality data is the bottleneck to AGI.
Consider the trajectory. In 2020, labeling sentiment as positive/negative/neutral had a low-quality ceiling (anyone could do it) and a high automation risk (models now handle this).
By 2023, evaluating RLHF preference pairs required judgment about which response better demonstrated helpfulness or honesty, creating a medium-quality ceiling with medium automation risk.
In 2025, debugging frontier model reasoning chains requires identifying where logic breaks down in multi-step proofs, creating an unlimited quality ceiling with low automation risk because this work trains the automation itself.
What tier structures reveal about measurement economics
The pattern matters: as AI capabilities advance, the work shifts from tasks models can automate to tasks that train models toward capabilities they haven't yet achieved. This means expertise becomes more valuable over time, not less.
Our tier structure reflects this reality:
Workers earning $20–$30+/hr demonstrate good writing, critical thinking, and attention to detail — thousands of workers can do this competently, so value comes from consistency and reliability.
Workers earning up to $60/hr for coding work provide domain expertise that evaluates algorithmic elegance (not just syntax correctness), assesses code quality, or identifies edge cases requiring specialized programming knowledge — hundreds of workers can do this competently.
Workers earning $50–$100+/hr for STEM and professional work assess scientific reasoning quality (not just fact accuracy) and apply regulatory context, ethical standards, and domain-specific quality criteria from mathematics, physics, biology, chemistry, law, finance, or medicine — dozens of workers can do so at the level of frontier model training.
The compensation jump isn't arbitrary. It reflects measurement reality: we can verify general quality through automated validators and statistical patterns, but expert-level quality requires expensive human verification.
Leverage existing expertise rather than building entirely new domains
Rather than trying to "learn new fields" to access higher tiers, identify where your existing knowledge creates quality advantages.
If you have a coding background, your edge is recognizing when AI-generated code works but creates technical debt, or when solutions follow best practices rather than merely passing tests — you already developed this taste through years of debugging and code review.
If you have a STEM background, your edge is assessing whether reasoning chains support their conclusions or identifying methodological bias—your education taught you how experts evaluate quality.
If you have a professional background, your edge lies in applying contextual judgment in ambiguous situations — your career has taught you to navigate complexity.
Preparation for specialized assessments means refreshing fundamentals, not building entirely new expertise. For coding specialization, review common algorithmic patterns and language-specific best practices while focusing on evaluating code quality rather than writing code.
For the STEM specialization, review fundamental principles and common misconceptions, focusing on evaluating reasoning quality rather than fact accuracy. For professional specialization, review current regulatory standards, focusing on contextual appropriateness rather than technical correctness.
The goal is to demonstrate that your existing expertise enables quality judgments that general workers can't make and automated systems can't verify. As models get more capable, this work becomes more valuable because the gap between "passing automated checks" and "actually advancing model capabilities" widens.
Explore premium AI training jobs at DataAnnotation
Most platforms position AI training as gig work where you earn side income by clicking through microtasks. At DataAnnotation, we position it as contributing to AGI development, where your judgment determines whether billion-dollar training runs advance capabilities or optimize for the wrong objectives.
The difference matters. When you evaluate AI responses for technology platforms, your preference judgments influence how models balance helpfulness against truthfulness, how they handle ambiguous requests, and whether they develop reasoning capabilities that generalize or just memorize patterns.
This work shapes systems that millions of people will interact with.
Getting from interested to earning takes five straightforward steps:
- Visit the DataAnnotation application page and click “Apply”
- Fill out the brief form with your background and availability
- Complete the Starter Assessment, which tests your critical thinking and attention to detail
- Check your inbox for the approval decision (which should arrive within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. We stay selective to maintain quality standards. Just remember: you can only take the Starter Assessment once, so prepare thoroughly before starting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI — and you have the expertise to contribute.
.webp)
JP is a software engineer turned digital marketer based in Texas. He graduated from the University of Texas at Dallas with a degree in Software Engineering and began his career as a fullstack developer in fintech. Drawing on his technical background, JP transitioned into digital marketing freelancing, where he combines his engineering expertise with creative strategy. He brings a unique blend of technical and marketing skills to the DataAnnotation team.
Related posts


Get ahead in a changing workforce.
No recruiters. No interviews. Just meaningful work and real compensation.